Best Mac For Large Language Models

Hey all, I’ve been experimenting with running some large language models locally, like Llama-2, Mistral and Mixtral locally and these things are beastly and take tons of memory and GPU power!
But with the right Mac, you can totally run them yourself and take advantage of all that AI goodness. I’ve tried a bunch of different setups so let me break down what worked well based on the model size.
First let me tell you what is the best Mac model with Apple Silicone for running large language models locally.
When evaluating the price-to-performance ratio, the best Mac for local LLM inference is the 2022 Apple Mac Studio equipped with the M1 Ultra chip – featuring 48 GPU cores, 64 GB or 96 GB of RAM with an impressive 800 GB/s bandwidth.
Its robust architecture is tailored to efficiently handle the demands of large language models form 7B to 70B parameters.
The Apple Silicone unified memory architecture outperforms PC setups that rely solely on CPU and RAM for inference, offering significantly higher memory bandwidth. This advantage is crucial for the efficient processing of large language models, where traditional PC configurations fall short.
For those of you who prioritize mobility and cannot opt for a stationary solution like the Mac Studio, the best laptop alternative for large language model inference is the MacBook Pro equipped with the M2 Max chip and 64 GB of RAM. This configuration offers a blend of portability and power, making it ideal for those on the move.
M1 Ultra token generation and prompt eval speed:
| Model size | Quantization | Token generation (t/s) | Prompt eval speed (t/s) |
|---|---|---|---|
| 7B | 4-bit | 74.5 | ~770 |
| 7B | 8-bit | 55.6 | ~780 |
| 13B | 5-bit | 24.5 | ~125 |
| 13B | 8-bit | 26.5 | ~111 |
| 34B | 3-bit | 12.3 | ~65 |
| 34B | 4-bit | 13.4 | ~60 |
| 34B | 8-bit | 13.2 | ~60 |
| 70B | 2-bit | 8.5 | ~33 |
| 70B | 5-bit | 6.5 | ~24 |
| 70B | 8-bit | 6 | ~20 |
| 180B | 3-bit | 3.5 | ~5 |
Before we check some Mac models, let’s establish some memory requirements. Here’s what you’d need for different model sizes if quantized to 4-bits:
- 7 billion parameters – 5GB RAM
- 13 billion parameters – 8GB RAM
- 33 billion parameters – 20GB RAM
- 46 billion parameters (Mixtral 8x7B) – 26GB RAM
- 65 billion parameters – 40GB RAM
- 70 billion parameters – 41GB RAM
Apple Silicone (M1/M2/M3/M4) for large language models
The great thing about Apple’s Silicone chips is the unified memory architecture, meaning the RAM is shared between the CPU and GPU. This is way more efficient for inference tasks than having a PC with only CPU and RAM and no dedicated high-end GPU.
Keep in mind that you can use around 70-75% of the unified memory for Metal (GPU) accelerated inference. However there are ways to overcome this limit and use the entire memory for GPU inference.
Lets see how different generations of Apple silicone M chipset scale with LLM inference and prompt processing.
Price and inference speed comparison between different Mac models with Apple Silicone chips:
The table represents Apple Silicon benchmarks using the llama.cpp benchmarking function, simulating performance with a 512-token prompt and 128-token generation (-p 512 -n 128), rather than real-world long-context scenarios. It is designed to illustrate relative performance and was generated using data from an older version of llama.cpp. Newer versions of the software are expected to provide better performance.
| Chip generation | 8-bit PP | 8-bit TG | 4-bit PP | 4-bit TG | Price | Price/TG |
|---|---|---|---|---|---|---|
| M2 Pro (16) M1 Pro (16) |
288.46 270.37 |
22.7 22.34 |
294.24 266.25 |
37.87 36.41 |
$1,800.00 (32GB) $1,639.00 (32GB) |
$47.61 $45.15 |
| +6.69% | +1.61% | +10.51% | +4.01% | |||
| M2 Max (38) M1 Max (32) |
677.91 537.37 |
41.83 40.2 |
671.31 530.06 |
65.95 61.19 |
$3,139.00 (64GB) $2,899.00 (64GB) |
$47.59 $47.37 |
| +26.15% | +4.05% | +26.65% | +7.78% | |||
| M2 Ultra (60) M1 Ultra (48) |
1003.16 783.45 |
62.14 55.69 |
1013.81 772.24 |
88.64 74.93 |
$3,999.00 (64GB) $3,059.00 (64GB) |
$45.11 $40.82 |
| +28.04% | +11.58% | +31.28% | +18.29% | |||
| M2 Ultra (76) M2 Max (38) |
1248.59 677.91 |
66.64 41.83 |
1238.48 671.31 |
94.27 65.95 |
$4,999.00 (64GB) $3,139.00 (64GB) |
$53.02 $48.41 |
| +84.24% | +59.47% | +84.53% | +43.06% | |||
| M2 Ultra (76) M2 Ultra (60) |
1248.59 1003.16 |
66.64 62.14 |
1238.48 1013.81 |
94.27 88.64 |
$4,999.00 (64GB) $3,999.00 (64GB) |
$53.02 $45.11 |
| +24.43% | +7.23% | +22.19% | +6.33% | |||
| M3 Pro (18) M2 Pro (19) |
344.66 344.50 |
17.53 23.01 |
341.67 341.19 |
30.74 38.86 |
$2,799.00 (32GB) $2,400.00 (32GB) |
$91.05 $61.76 |
| 0.004% | -31.26% | -0.014% | -26.41% | |||
| M3 Max (40) M2 Max (38) |
757.64 677.91 |
42.75 41.83 |
759.7 671.31 |
66.31 65.95 |
$3,899.00 (64GB) $3,139.00 (64GB) |
$58.79 $47.59 |
| +11.76% | +2.20% | +13.17% | +0.55% | |||
| M4 Pro (20) M3 Pro (18) |
449.62 344.66 |
30.69 17.53 |
439.78 341.67 |
50.74 23.01 |
N/A |
N/A |
| +30.5% | +75.07% | +28.71% | +120.5% | |||
| M4 Max (40) M3 Max (40) |
891.94 757.64 |
54.05 42.75 |
885.68 759.7 |
83.06 66.31 |
N/A | |
| +17.7% | +26.43% | +16.58% | +25.26% |
*PP – prompt processing
*TG – token generation
*original data is provided by this Github llama.cpp discussion.
Apple Silicon Chips and Prompt Processing: Speed Expectations
Apple Silicon chips (M1 to M4) have transformed Macs, but they’re not as fast at handling large language models (LLMs) as dedicated GPUs, which surprises many new users. Apple Silicon chips excel in multitasking and efficiency but lack the raw speed of GPUs optimized for machine learning.
When working with LLMs on Apple Silicon, the initial processing time is often the slowest, especially when feeding the model a large amount of context (text history). This occurs because the model must process and store all this data at once, consuming considerable resources and making this first pass relatively slow. This is because prompt processing is compute-bound, which is why NVIDIA GPUs are significantly faster than Apple Silicon – they simply have more raw computational power (measured in FLOPs). On the other hand, token generation is bandwidth-bound, where the difference in performance is much smaller.
For users running models that require a lot of initial context – for example, analyzing entire documents or handling extensive chat history in one go – the Mac’s efficiency can be put to the test, and they might find that processing takes significantly longer than expected. This is particularly the case for high-parameter models (like Llama 3.1 70B), which not only need more memory but also more time to parse large contexts.
For example, the M2 Ultra can process a 32K-token context on a 70B Llama 3.1 model (quantized to 5-bit) in approximately 9 minutes.
| Model / Quantization / Ctx | Initial Time (s) | Initial Speed (T/s) | Shifted Time (s) | Shifted (T/s) |
|---|---|---|---|---|
| 155b q8 @ 8k | 167.77 | 44.79 | 8.66 | 4.27 |
| 120b q8 @ 32k | 778.50 | 41.39 | 8.47 | 5.43 |
| 120b q8 @ 16k | 292.33 | 52.82 | 7.51 | 5.46 |
| 120b @ 4k | 60.47 | 56.56 | 6.60 | 3.94 |
| 70b q5 @ 32k | 526.17 | 61.20 | 2.93 | 9.55 |
| 70b q5 @ 8k | 93.14 | 80.67 | 2.71 | 22.50 |
| 34b q8 @ 65k | 794.56 | 77.25 | 799.03 | 75.21 |
| 34b q8 @ 32k | 232.20 | 130.41 | 1.78 | 15.13 |
| 34b q8 @ 8k | 26.71 | 198.32 | 1.56 | 24.98 |
| 13b q8 @ 8k | 12.56 | 487.66 | 0.69 | 43.67 |
| 7b q8 @ 32k | 59.73 | 514.38 | 0.52 | 38.61 |
Managing Speed with Context Shifting
The good news? Speed can improve significantly in chat-based, incremental prompts if you use Koboldcpp context shifting. In these scenarios:
- Each new prompt builds on recent history, and the model processes only the latest messages rather than the entire conversation.
- Context shifting clears out old messages as new ones come in, keeping response times manageable even with big models.
Token Generation and prompt processing
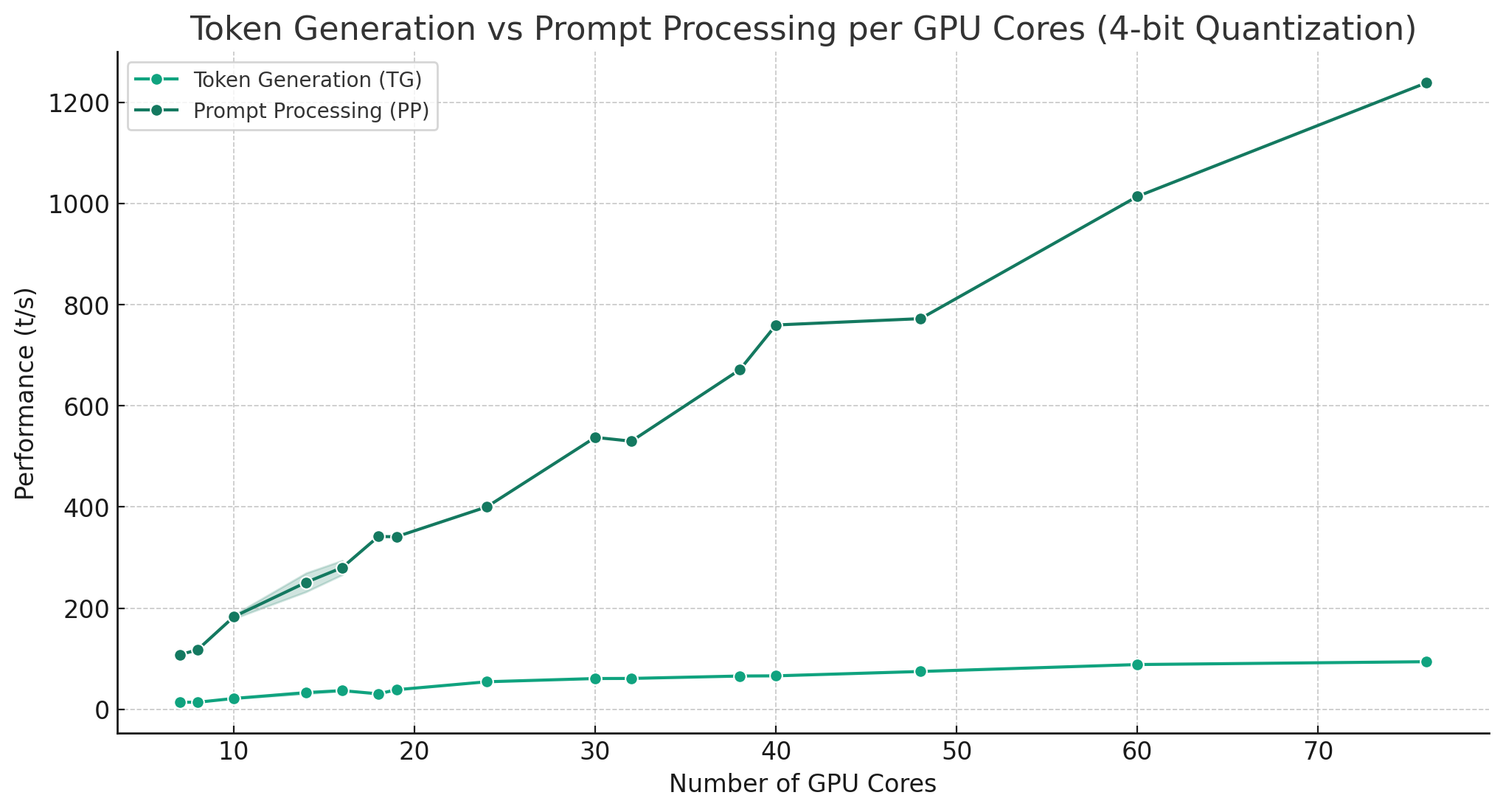
The graph above displays the relationship between the number of GPU cores and their performance in terms of Token Generation (TG) and Prompt Processing (PP) for 4-bit quantization (Q4_0)
Token Generation (TG) Scaling: TG generally shows an increasing trend with the number of GPU cores. This indicates that as the number of cores increases, the capability for token generation also increases, suggesting a positive correlation between the two.
Comparison with Prompt Processing (PP): PP also scales positively with the number of GPU cores, similar to TG. However, the rate of increase for PP appears to be more pronounced than for TG, especially at higher core counts. This suggests that while both metrics benefit from more GPU cores, PP may be more sensitive or responsive to increases in core counts than TG.
Overall, both TG and PP improve with an increase in GPU cores, but PP seems to have a stronger correlation with the number of cores.
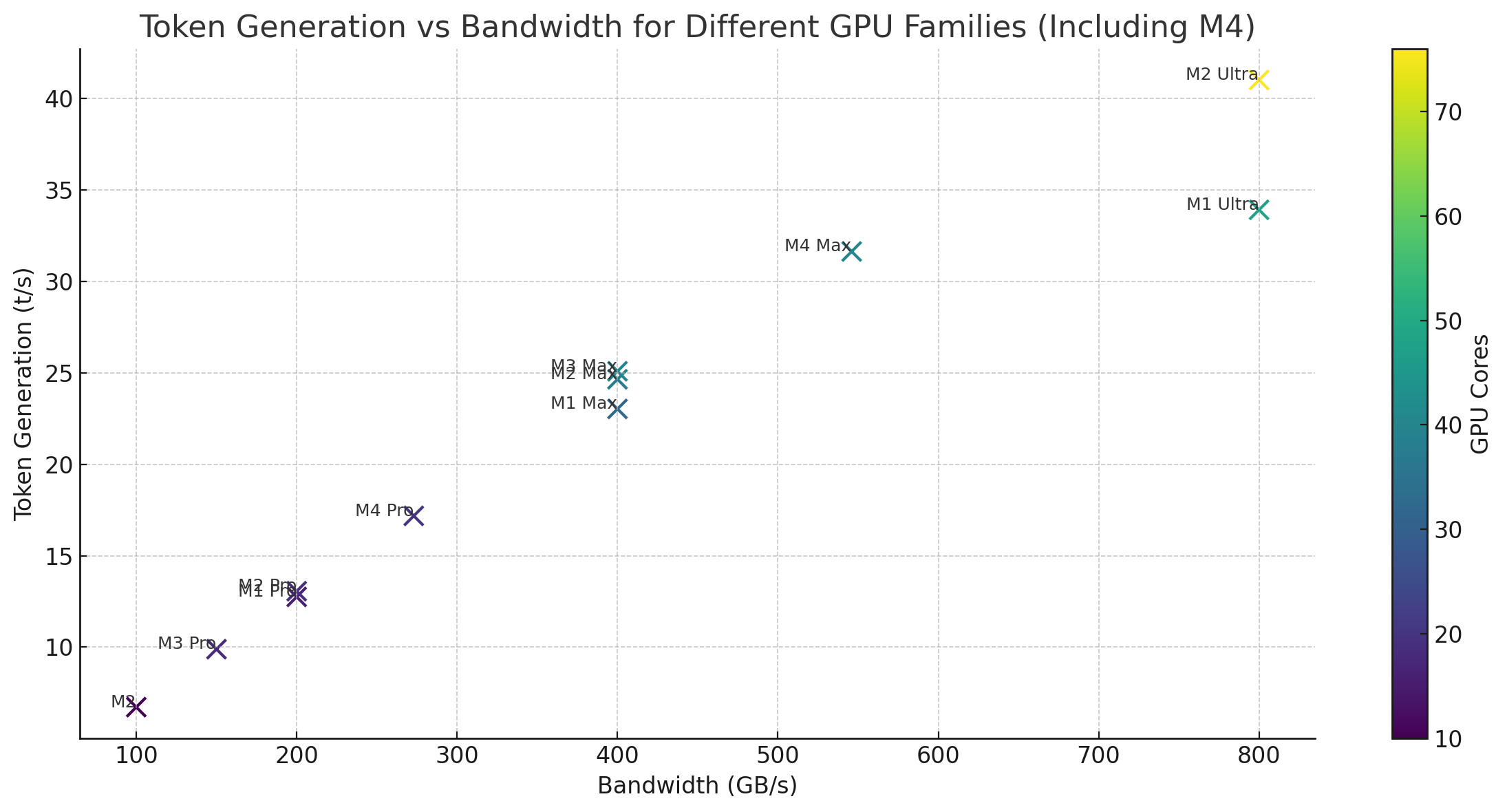
The scatter plot above illustrates the relationship between bandwidth (GB/s), token generation (TG in tokens per second), and the number of GPU cores for different Apple silicone chips.
In terms of pure token generation there is a noticeable trend where higher bandwidth often corresponds to higher TG performance. This suggests that bandwidth is indeed an important factor in token generation efficiency.
The plot shows that chips with similar bandwidth and different core counts can perform quite close to each other. This again means that the core count is much more important for prompt processing than token generation.
In summary, while the number of GPU cores is important, the bandwidth is a crucial factor influencing token generation performance. The analysis shows that chips with higher bandwidth generally offer better TG performance, but chip-specific characteristics and architecture also significantly impact the overall efficiency.
Mac vs PC for large language models
If you are going back and forth trying to decide between building a PC for LLM with RTX 3090/4090 GPUs or getting a Mac Studio Ultra for running large language models locally. Here’s a quick rundown of the pros and cons of each:
RTX 4090 vs Mac Studio
The 4090 GPU setup would deliver faster performance than the Mac thanks to higher memory bandwidth – 1008 GB/s. We’re talking 2x higher tokens per second easily. You can also train models on the 4090s. Downsides are higher cost ($4500+ for 2 cards) and more complexity to build.
The Mac Studio Ultra gives you fast (800 GB/s) unified VRAM (up to 192GB!). This means you can run multiple models at once no problem. Cost is lower (for Mac Studio M1 Ultra) at $3100 for 64GB refurbished models and around $2500 for second hand model. No assembly or driver hassles. But you can only run certain model types (GGUF) and no training.
So in summary, the 4090 machine will beat the Mac on speed but the Mac gives you simplicity and more VRAM. It just depends if you want quality (4090 speed) or quantity (Mac VRAM capacity).
RTX 3090 vs Mac Studio
Another option is to use the older RTX flagship – 3090. It is slower than the RTX 4090 but still better than M1/M2 Ultra in terms of inference speed and prompt processing.
| Attribute | 2x RTX 3090 7B | M1 Ultra 7B | 2x RTX 3090 70B | M1 Ultra 70B |
|---|---|---|---|---|
| Model size | 3.56 GiB | 3.56 GiB | 36.20 GiB | 36.20 GiB |
| Params | 7B | 7B | 70B | 70B |
| Quantization | 4-bit | 4-bit | 4-bit | 4-bit |
| Backend | CUDA | Metal | CUDA | Metal |
| Prompt Processing (t/s) | 1178.6 | 772.24 | 179.29 | 40.29 |
| Token Generation (t/s) | 87.34 | 74.93 | 21.17 | 8.17 |
You can find new RTX 3090 cards for around $1500 each. To run a 70 billion parameter model, you’ll need two of these cards for a total GPU cost of $3000. However, there are many used/second-hand RTX 3090 options that can bring the total system price down quite a bit.
For example a dual RXT 3090 (second hand) Ryzen 5 7600 with 64GB RAM desktop system costs around $2900, which is similar in price with a refurbished Mac Studio M1 Ultra with 64GB memory.
You can use a Mac to run models with better energy consumption, quiet, and with less hassle. But you do sacrifice training ability and max inference speed. Choose based on your priorities!
Mac for 7B and 13B parameter model
For smaller 7 billion parameter models, I was able to get good performance on a Mac Mini and MacBook Air with M2 chip and 16GB of unified memory. The 8-core GPU gives enough oomph for quick prompt processing. However my suggestion is you get a Macbook Pro with M1 Pro chip and 16 GB for RAM. It will work perfectly for both 7B and 13B models.
Another option here will be Mac Studio with M1 Ultra and 16Gb of RAM.
Mac for 33B to 46B (Mixtral 8x7b) parameter model
Once I got into the 33-46 billion parameter range, I had to step up a 16″ M2 Pro MacBook Pro with an M1 Max chip. The 24-core GPU and 64 GB (200 GB/s bandwidth) memory really seemed like the sweet spot for snappy response times.
The MacBook Pro models with M1, M2, or M3 Pro chips are also an option. However, these MacBooks are limited to a maximum of 32GB of RAM. With that constraint, you’ll only be able to run 4-bit quantized models. Additionally, Apple’s silicone chips can only allocate about 65% of the total RAM to the GPU when used with 32GB of RAM. Keep in mind that with these setup you would not be able to run 4-bit MoE Mixtral 8x7B model.
Mac for 70B + parameter model
When I really wanted to push it with the 65-70 billion monsters, that’s when the Mac Studio came in handy. I tested both the M1 Ultra and M2 Ultra models. The M2 Ultra with its crazy 76-core GPU and 192GB memory can run even 180 billion parameter models without breaking a sweat! However the 2022 Mac Studio with M1 Ultra chip and 64Gb of ram is the best Mac for this size of large language models.
So if you want to play around with huge models for fun or profit, get yourself a Mac Studio Ultra or maxed out MacBook Pro.

Allan Witt
<p>Allan Witt is the co-founder and Editor-in-Chief of Hardware-Corner.net. Computers and the web have fascinated him since childhood. In 2011, he began training as an IT specialist at a mid-sized company while launching a tech blog on the side—quickly discovering a passion for writing about hardware and technology.</p> <p>After completing his training, Allan worked as a system administrator for two years. Alongside that, he started building and upgrading custom gaming PCs at a local hardware shop. What began as a part-time project grew into a full-time career. Today, his work also focuses on building and optimizing PC systems for local AI and LLM workloads, combining hands-on experience with a passion for making complex tech easy to understand.</p>5 Comments
Submit a Comment
Related
Desktops
Best GPUs for 600W and 650W PSU
A high-quality 500W PSU is typically sufficient to power GPUs like the Nvidia GeForce RTX 370 Ti or RTX 4070.
Guides
Dell Outlet and Dell Refurbished Guide
For cheap refurbished desktops, laptops, and workstations made by Dell, you have the option…
Guides
Dell OptiPlex 3020 vs 7020 vs 9020
Differences between the Dell OptiPlex 3020, 7020 and 9020 desktops.
For running local LLM do you think an m4 pro mini 64gb RAM is better than m4 max 36 GB?
I’d go with the M4 Max in this case. The extra RAM on the Pro is tempting if you’re trying to squeeze in massive 70B models, but they’re probably going to run pretty slow anyway. The Max’s higher memory bandwidth means faster token generation and a much snappier experience overall – especially with models like Qwen3-32B and Qwen3 30B MoE, which are super capable and don’t need as much memory. Plus, those models run well on the 36GB Max with plenty of room left for context. For me, speed and responsiveness matter more than just being able to load a bigger model.
Hello.
For strictly playing with LLMs and AI tools like Amuse, not something serious, what would you get, M1 Max with 64GB or M4 Pro with 24 GB?
Mind you, this is coming from a Windows PC and this would become my primary system.
In my case, both cost the same but the M1 Max comes with a 1 TB SSD.
For playing with LLMs, the M1 Max with 64GB is the better choice.
It has higher memory bandwidth (400 GB/s vs 273 GB/s on the M4 Pro) and more RAM. It will be great for MoE models like Qwen3 30B A3B and longer context windows. The 1TB SSD is a nice extra, too.
I just got a m1 max macbook 32core GPU 64GB for testing, its a neat toy for LLM’s.
It can run 70b q4 models at 8-9 T/S with MLX and 6-7 T/S with GGUF.
One thing to emphasize is that MLX IS SLOW! at prompt processing, so with larger models you almost loose more time processing than you gain generating. So be skeptical of all the hype.
I haven’t decided yet if its useful enough or ill return it.
Also note that the default GPU allocation is 3/4 so you get 48GB VRAM with a 64GB macbook.
This can be changed, but obviously, you need something for your desktop.
It seems like the AMD ai pro max is a complete dud and this was cheaper than most of the mini PC’s with that CPU anyway.
Im not a Mac person, the screen is sharp, but very reflective, and keyboard and trackpad is garbage compare to a good thinkpad.
OS X is less naggy and bloated compared to Windows but obviously more than Linux. The GUI is very responsive compared to Linux, but its very much, do it my way or leave it.
So far, if you insist on running LLM offline and want to run 70b ish size models its the simplest cheapest option that has the option of being mobile and uses very little electricity in energy poor European countries.
A much more serious setup would be dual 3090 with Linux, but thats basically a whole new computer for most.
I would not bother with 128GB Mac’s unless its an Studio Ultra, the 32core GPU is just barely fast enough for experimenting with 70b q4 models. From what ive seen, significant GPU speedup per core only happens at the M4 series.
For models fitting in 24GB or 16 GB VRAM, im not sure if would make more sense getting a laptop with a NVidia GPU. They would be more expensive and less mobile, but faster.
If you dont need a laptop and dont need to run 70b models, a few 3060 or a 3090 or even a 7900 xtx will give more performance for the money.