How to download Llama-2, Mistral, Yi and Mixtral LLM?
Since I’ve spent considerable time exploring the Hugging Face repositories, I’ve decided to put together a guide on downloading various Large Language Models (LLMs) based on their file formats. This guide is tailored for those looking to install and operate Llama-2, Mistral, Mixtral, or similar quantized large language models on their personal computer. It’s important to note that running these models requires robust hardware (Mac and PC) and specific inference software for loading and interacting with them.
GGUF Format
GGUF, crafted by Georgi Gerganov (creator of llama.cpp), is a binary format for AI models like LLaMA and Mistral. It’s great for fast loading and works well with Apple Silicon (M1/M2/M3 Mac models). Here’s how to get it:
Direct Download
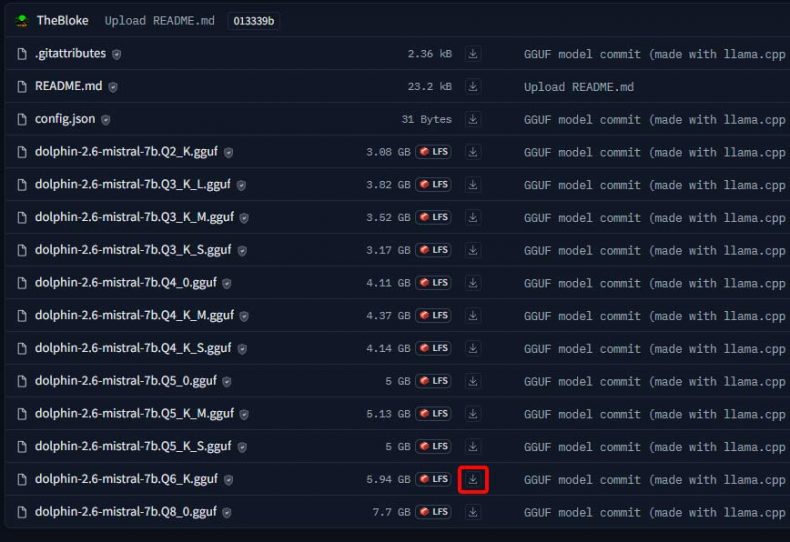
- Go to the TheBloke repo on Hugging Face and select GGUF model (e.g., TheBloke/dolphin-2.6-mistral-7B-GGUF).
- Choose the right quantization for your hardware. (e.g., for an RTX 3060 12GB you can select the 8-bit version).
- In ‘Files and Versions‘ tab, pick the model and click the download arrow next to it.
- Save the file in your model directory
Command Line Download
Use wget in the terminal:
wget https://huggingface.co/TheBloke/dolphin-2.6-mistral-7B-GGUF/resolve/main/dolphin-2.6-mistral-7b.Q8_0.gguf?download=trueLM Studio Download
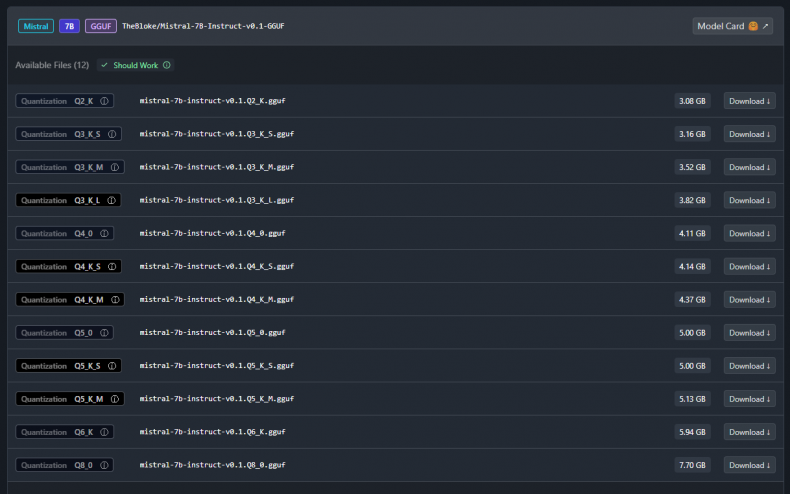
A highly convenient method for downloading models is through the software you’re using. LM Studio, for instance, features a search bar that enables you to easily download any GGUF model from Hugging Face. Simply type the model’s name into the search bar, select the desired model from the search results, and then click the download button next to the quantized version you require.
Ollama
Ollama offers a similar functionality, but it operates through the command line. You can use the command:
ollama run mistralThis command triggers the download and loading of the model if it’s not already present locally. Ollama comes with a predefined set of models but also supports manually downloaded GGUF file models and use them with model file. This flexibility allows you to work with a wide range of models beyond those initially set in Ollama’s library.
Software for GGUF: llama.cpp, Ollama, LM Studio, GPT4All, Koboltcpp.
GPTQ Format
The GPTQ file format is structurally different from GGUF. Unlike GGUF, it isn’t comprised of a single file but rather a combination of files. Additionally, this format doesn’t offer a variety of quantizations; it exclusively supports 4-bit quantization. Models with weights quantized in this format are designed to be loaded solely on a GPU.
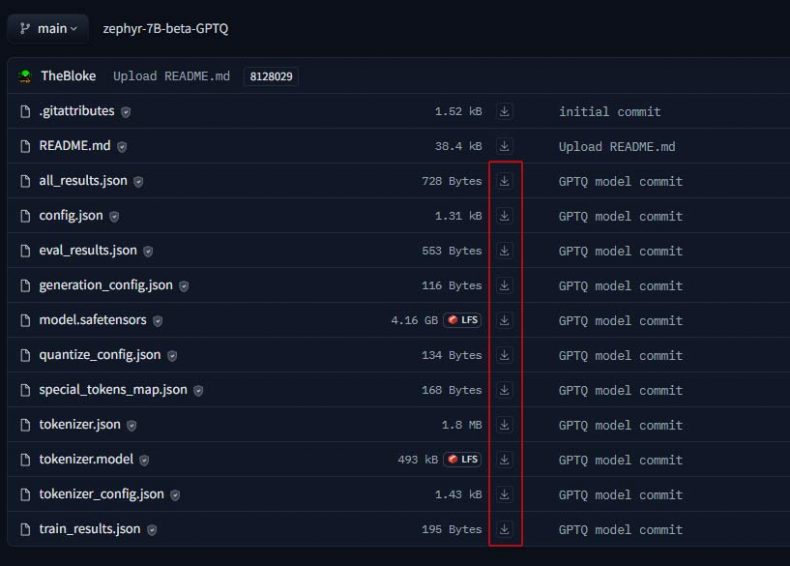
Direct Download
- Make a directory for the model.
- Visit the TheBloke repo and select GPTQ model (e.g., TheBloke/zephyr-7B-beta-GPTQ)
- Download all files under ‘Files and Versions’ tab.
Download with Git
Since every Hugging face model repo is a Git repository, you can totally use Git to download the models, which is pretty handy. Hoverer, you have to make sure you’ve got Git Large File Storage (LFS) installed before you go ahead and clone the repo. In my case I’ll use zephyr-7B-beta-GPTQ model as an example.
Check if you have Git LFS:
git lfs versionIf you don’t have git-lfs you have to install it. On Windows download from the official site. For Linux and macOS use the package manager.
#Linux Debian/Ubuntu
sudo apt install git-lfs
#macOS
brew install git-lfsTo download LLM model with Git do the following:
git lfs install
git clone https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ
You can also download trough SSH:
git lfs install
git clone [email protected]:TheBloke/zephyr-7B-beta-GPTQ
Software for GPTQ: ExLlama, ExLlamaV2, vLLM, Aphrodite Engine.
EXL2 Format
EXL2 is an upgraded version of the GPTQ file format, developed by turboderp responsible for creating Exllama and ExllamaV2. In contrast to GPTQ, EXL2 is a faster and more optimized format, supporting a wider range of quantizations including 2, 3, 4, 5, 6, and 8-bit. For those prioritizing inference speed, EXL2 stands out as the quickest file format, particularly for batch 1 inference.
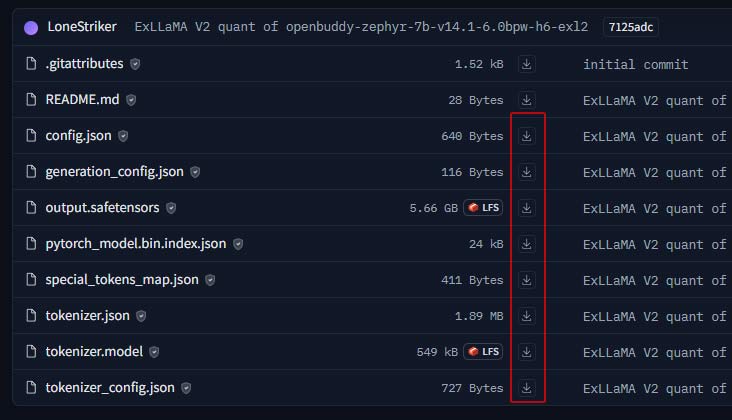
Direct Download
- Make a directory for the model.
- Visit the LoneStriker’s repo and select exl2 model
- Download all files under ‘Files and Versions’ tab.
Software for EXL2: ExLlamaV2
Download using Git
You can use the same Git method descript previously in the GPTQ section to download the model files.
AWQ Format
AWQ is a 4-bit weight quantization method, faster and sometimes more accurate than GPTQ. To download:
Direct Download
- Make a directory for the model.
- Visit the TheBloke repo and select AWQ model
- Download all files under ‘Files and Versions’ tab.
Download using Git
You can use the same Git method descript previously in the GPTQ section to download the model files.
Software for AWQ: AutoAWQ, vLLM, Aphrodite Engine, Hugging Face TGI
Downloading Through Text Generation Web UI
For all formats, you can use Text Generation Web UI:
- Go to the Model tab.
- Enter the model’s repo/name in the first field (e.g., TheBloke/zephyr-7B-beta-GPTQ or TheBloke/zephyr-7B-beta-GGUF).
- For GGUF, also specify the quantization type in the second field.
- Hit download, and wait for the model to download.
- Use the model selector to load it.
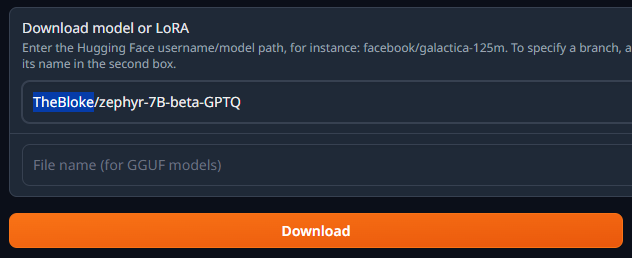
For GPTQ, EXL2, and AWQ use the top form filed only
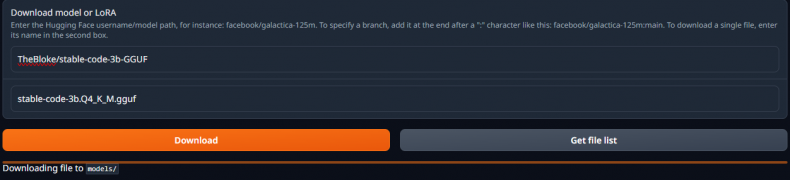
For GGUF model use both fields under ‘Download model or LoRA’
Hope this helps you get started with LLMs on your PC!