Hardware Insights
-
Nov. 11, 2025 / Hardware Insights
Building a Multi-GPU LLM Workstation: Choosing the Right Motherboard for 6 – 10 GPUs
If you want to run larger local models like Qwen3 235B A22B or GLM-4.6 355B fully in VRAM, you quickly run into the problem of scale. Even with 4-bit quantization, Qwen3 235B A22B is about 135 GB and GLM-4.6 355B is roughly 206 GB. On budget-tier GPUs such as RTX 3090 (24 GB VRAM), that...

-
Nov. 10, 2025 / Hardware Insights
GPT-OSS 120B: Offloading MoE Layers to CPU Boosts RTX 3090 and 5090 Performance
I’ve been testing the --n-cpu-moe flag in llama.cpp to see how much it improves performance with large Mixture of Experts models. The standard method of splitting layers between the GPU and CPU can be slow for these models. This flag offers a more targeted approach by moving just the expert layers to system RAM while...

-
Nov. 4, 2025 / Hardware Insights
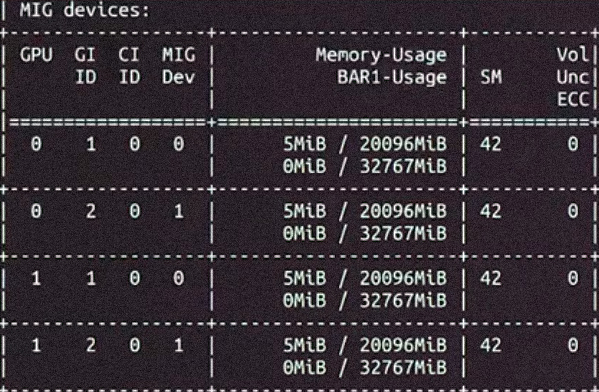
Running vLLM for Local LLMs on Mixed GPUs? MIG Might Just Make It Work.
When I recently helped set up an LLM inference server for a client, I ran into a problem that may sound familiar to anyone mixing different GPUs. I had an RTX Pro 6000 Workstation (95 GB VRAM) and an RTX 5090 (32 GB VRAM). The goal was simple: run vLLM setup without wasting available memory....

-
Nov. 3, 2025 / Hardware Insights
Inside PewDiePie’s $41,000 AI PC: 424GB of VRAM for Local LLMs
When one of YouTube’s biggest creators decides to build a personal AI supercomputer, the local LLM scene takes notice. PewDiePie’s journey into AI hardware has produced a multi-GPU, 424GB VRAM workstation that many enthusiasts dream of. While his budget is far beyond the average builder, his component choices and setup offer a valuable blueprint for...

-
Nov. 2, 2025 / Hardware Insights
The Definitive GPU Ranking for LLMs: Token Generation & Prompt Processing Performance
At Hardware Corner, we set out to create a data-driven benchmark hierarchy for local LLM inference – focusing on the two workloads that define real-world performance: prompt processing and token generation. Using llama.cpp’s latest llama-bench on Ubuntu 24.04 with CUDA 12.8, we measured a wide range of GPUs across model sizes, context lengths, and quantization...

-
Oct. 24, 2025 / Hardware Insights
Best PC Builds for Local LLMs: From 7B to 123B Models
This guide presents several PC build options at different price points for enthusiasts looking to run large language models (LLMs) on their local machines. These are templates designed for performance and value in LLM inference. You can adjust them based on component availability and your specific budget. At the moment, RAM prices are unusually high,...

-
Oct. 11, 2025 / Hardware Insights
What Makes Apple Silicon and Strix Halo Good at Running Local LLMs?.
For years, the formula for running large language models locally has been simple: get as much VRAM as you can afford. This usually meant building complex, power-hungry desktop rigs with multiple GPUs or hunting for deals on used server hardware. But a new class of hardware, powered by Apple Silicon and AMD’s “Strix Halo” APUs,...

-
Sep. 11, 2025 / Hardware Insights
GPU First or Model First? The Right Way to Decide on Local LLM Hardware
Let’s be honest: cloud LLMs are incredibly powerful and mostly free. GPT-5, Gemini Pro, Claude Sonnet 4 – you can use them for almost unlimited queries without hitting hard limits. I personally combine Gemini and ChatGPT when one hits a rate limit, and it works perfectly. So why would you want to run models locally?...