GPUs
-
Apr. 16, 2026 / Hardware Insights
What hardware you need for MiniMax-M2.7 230B (A10B) in 4-bit
Running MiniMax-M2.7 230B locally requires extreme VRAM, even with 4-bit quantization, and a dual high-end GPU setup is the practical baseline today. This article shows real VRAM usage and performance from a dual RTX Pro 6000 Blackwell system using MXFP4 quantization, with a focus on hardware limits and inference speed. Test setup and model details...

-
Apr. 7, 2026 / Hardware Insights
What GPU for Running OpenClaw Locally
Running OpenClaw locally is not the same as running a simple chat model. Once you move into agentic workflows with tool calling, long system prompts, and multi-step reasoning, the hardware requirements shift in a very specific way. VRAM becomes the primary constraint, memory bandwidth defines responsiveness, and model size directly affects reliability. This article focuses...

-
Feb. 26, 2026 / Hardware Insights
How Memory Chips Determine GPU Memory Bandwidth for Local LLM Inference
If you are running quantized LLMs locally, especially 4-bit models, memory bandwidth usually matters more than raw CUDA core count. Once the model fits in VRAM, inference speed is largely determined by how fast the GPU can stream weights from VRAM into the tensor cores. For 7B models this is less obvious. For 34B, 70B,...

-
Feb. 26, 2026 / Hardware Insights
Qwen3.5 27B and Qwen3.5 35B: What Hardware Do You Actually Need? (GPU Benchmarks Inside)
Qwen3.5 27B fits comfortably on a 24 GB GPU up to 131k context in 4-bit, but becomes memory heavy at 262k. Qwen3.5 35B MoE in 4-bit is the more practical long-context model for 24 GB cards, and it is significantly faster in token generation despite having more total parameters. VRAM is still the main constraint,...

-
Jan. 26, 2026 / Hardware Insights
Best Computers for Running ClawdBot (OpenClaw) AI Assistant Locally
If you are running OpenClaw with a cloud model like Claude Opus, you do not need powerful hardware. Any modern low power system with 8 GB of RAM and a 6th+ gen Intel CPU is enough. If you want to run ClawdBot fully local with reliable tool usage and large context windows, hardware requirements scale...

-
Jan. 20, 2026 / Hardware Insights
How I Test GPUs for Local LLMs Before I Buy One
Learn how I test GPUs for local LLM inference before buying, using real workflows, llama.cpp, and rented RTX 3090 instances to measure VRAM, context length, and performance.
-
Nov. 17, 2025 / Hardware Insights
Best Black Friday 2025 GPU Deals for Local LLM Users
We’re tracking GPUs that make sense for LLM workloads and monitoring their prices now through Black Friday 2025, and we’re grouping them by VRAM since memory capacity determines which models and context lengths they can run, with bandwidth playing a major role in real-world throughput.

-
Nov. 4, 2025 / Hardware Insights
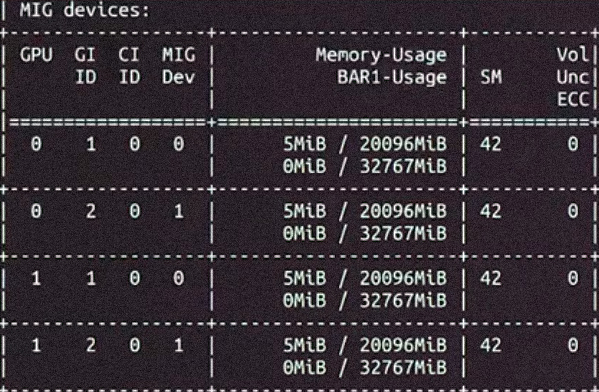
Running vLLM for Local LLMs on Mixed GPUs? MIG Might Just Make It Work.
When I recently helped set up an LLM inference server for a client, I ran into a problem that may sound familiar to anyone mixing different GPUs. I had an RTX Pro 6000 Workstation (95 GB VRAM) and an RTX 5090 (32 GB VRAM). The goal was simple: run vLLM setup without wasting available memory....

-
Nov. 3, 2025 / Hardware Insights
Inside PewDiePie’s $41,000 AI PC: 424GB of VRAM for Local LLMs
When one of YouTube’s biggest creators decides to build a personal AI supercomputer, the local LLM scene takes notice. PewDiePie’s journey into AI hardware has produced a multi-GPU, 424GB VRAM workstation that many enthusiasts dream of. While his budget is far beyond the average builder, his component choices and setup offer a valuable blueprint for...

-
Nov. 2, 2025 / Hardware Insights
The Definitive GPU Ranking for LLMs: Token Generation & Prompt Processing Performance
At Hardware Corner, we set out to create a data-driven benchmark hierarchy for local LLM inference – focusing on the two workloads that define real-world performance: prompt processing and token generation. Using llama.cpp’s latest llama-bench on Ubuntu 24.04 with CUDA 12.8, we measured a wide range of GPUs across model sizes, context lengths, and quantization...

-
Oct. 28, 2025 / LLM Benchmarks
LLM VRAM Usage Compared: Benchmarking Popular 8B–123B Models Across 4K–256K Contexts
As someone who runs language models locally, I know that VRAM is the one resource we can never have enough of. Every parameter, every token of context, and the growing KV cache all chip away at that precious memory. To cut through the speculation and get hard data, I decided to benchmark some of today’s...

-
Oct. 24, 2025 / Hardware Insights
Best PC Builds for Local LLMs: From 7B to 123B Models
This guide presents several PC build options at different price points for enthusiasts looking to run large language models (LLMs) on their local machines. These are templates designed for performance and value in LLM inference. You can adjust them based on component availability and your specific budget. At the moment, RAM prices are unusually high,...

-
Oct. 17, 2025 / LLM Benchmarks
RTX 4090 LLM Benchmarks: Performance Across 4K – 131K Context Sizes
I tested the RTX 4090 with five quantized models to measure real-world inference performance for local LLM workloads. This is the second article in my GPU benchmark series, following my recent RTX 5090 tests. I ran these benchmarks to provide concrete performance data across different model sizes and context lengths using llama.cpp. Testing Environment My...

-
Oct. 16, 2025 / LLM Benchmarks
RTX 5090 LLM Benchmark Results: 10K Tokens/sec Prompt Processing, 139K Context
I recently completed extensive local LLM inference benchmarks on the NVIDIA RTX 5090 32 GB. My primary focus was gathering raw performance data on critical metrics for the local enthusiast: prompt processing speed (PP), token generation throughput (TG), and the maximum context window I could sustain using 4-bit quantization (Q4_K_XL). My goal here is to...

-
Sep. 11, 2025 / Hardware Insights
GPU First or Model First? The Right Way to Decide on Local LLM Hardware
Let’s be honest: cloud LLMs are incredibly powerful and mostly free. GPT-5, Gemini Pro, Claude Sonnet 4 – you can use them for almost unlimited queries without hitting hard limits. I personally combine Gemini and ChatGPT when one hits a rate limit, and it works perfectly. So why would you want to run models locally?...

-
Sep. 10, 2025 / LLM Benchmarks
Can Three RTX 3090s Really Run GPT-OSS 120B with Max Context? I Put It to the Test
After testing the gpt-oss-20B model on a single RTX 3090, I had to push things further and see what the new heavyweight could do. In addition to the 20B model, OpenAI also released gpt-oss-120B, a massive 120-billion parameter open-weight Mixture-of-Experts (MoE) model with 5.1 billion active parameters. I first ran some experiments on an RTX...