LLM Benchmarks
-
Jan. 22, 2026 / Hardware Insights
We Tested GLM-4.7 Flash 30B MoE — Here’s the GPU You Actually Need
Z.ai released GLM 4.7 Flash only a few days ago, but meaningful local testing had to wait. The initial llama.cpp support was incomplete, and without proper fixes it was not possible to measure real performance. Those fixes have now landed, and with the latest llama.cpp build we were finally able to test the model properly...

-
Dec. 11, 2025 / Hardware Insights
We Tested Devstral 2 (24B & 123B) — Here’s the Hardware You Actually Need
Mistral AI has just released its new coding model, Devstral 2. We’ve been using its predecessor, Devstral Small, locally for code completion and have been very impressed with its performance. Early reports on Devstral 2 put it on par with other top models like Kimi K2 and Deepseek v3.2, so we were eager to get...

-
Nov. 10, 2025 / Hardware Insights
GPT-OSS 120B: Offloading MoE Layers to CPU Boosts RTX 3090 and 5090 Performance
I’ve been testing the --n-cpu-moe flag in llama.cpp to see how much it improves performance with large Mixture of Experts models. The standard method of splitting layers between the GPU and CPU can be slow for these models. This flag offers a more targeted approach by moving just the expert layers to system RAM while...

-
Nov. 2, 2025 / Hardware Insights
The Definitive GPU Ranking for LLMs: Token Generation & Prompt Processing Performance
At Hardware Corner, we set out to create a data-driven benchmark hierarchy for local LLM inference – focusing on the two workloads that define real-world performance: prompt processing and token generation. Using llama.cpp’s latest llama-bench on Ubuntu 24.04 with CUDA 12.8, we measured a wide range of GPUs across model sizes, context lengths, and quantization...

-
Oct. 28, 2025 / LLM Benchmarks
LLM VRAM Usage Compared: Benchmarking Popular 8B–123B Models Across 4K–256K Contexts
As someone who runs language models locally, I know that VRAM is the one resource we can never have enough of. Every parameter, every token of context, and the growing KV cache all chip away at that precious memory. To cut through the speculation and get hard data, I decided to benchmark some of today’s...

-
Oct. 17, 2025 / LLM Benchmarks
RTX 4090 LLM Benchmarks: Performance Across 4K – 131K Context Sizes
I tested the RTX 4090 with five quantized models to measure real-world inference performance for local LLM workloads. This is the second article in my GPU benchmark series, following my recent RTX 5090 tests. I ran these benchmarks to provide concrete performance data across different model sizes and context lengths using llama.cpp. Testing Environment My...

-
Oct. 16, 2025 / LLM Benchmarks
RTX 5090 LLM Benchmark Results: 10K Tokens/sec Prompt Processing, 139K Context
I recently completed extensive local LLM inference benchmarks on the NVIDIA RTX 5090 32 GB. My primary focus was gathering raw performance data on critical metrics for the local enthusiast: prompt processing speed (PP), token generation throughput (TG), and the maximum context window I could sustain using 4-bit quantization (Q4_K_XL). My goal here is to...

-
Sep. 16, 2025 / LLM Benchmarks
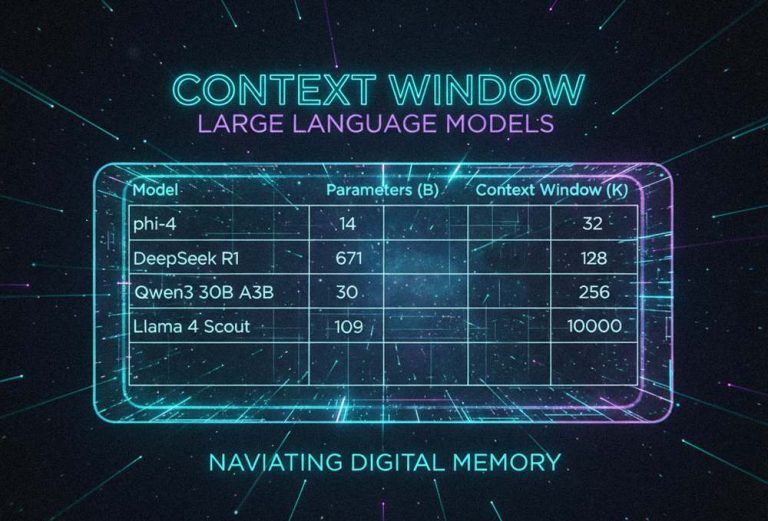
Local LLM Models and Their Max Context Windows: A Reference Table
When choosing a local LLM, one of the first specifications to check is its context window. The context size determines how many tokens you can feed into the model at once, which directly affects practical use cases like long-form reasoning, document analysis, or multi-turn conversations. For hardware enthusiasts running quantized models on limited VRAM, knowing...

-
Sep. 10, 2025 / LLM Benchmarks
Can Three RTX 3090s Really Run GPT-OSS 120B with Max Context? I Put It to the Test
After testing the gpt-oss-20B model on a single RTX 3090, I had to push things further and see what the new heavyweight could do. In addition to the 20B model, OpenAI also released gpt-oss-120B, a massive 120-billion parameter open-weight Mixture-of-Experts (MoE) model with 5.1 billion active parameters. I first ran some experiments on an RTX...