vLLM
-
Nov. 4, 2025 / Hardware Insights
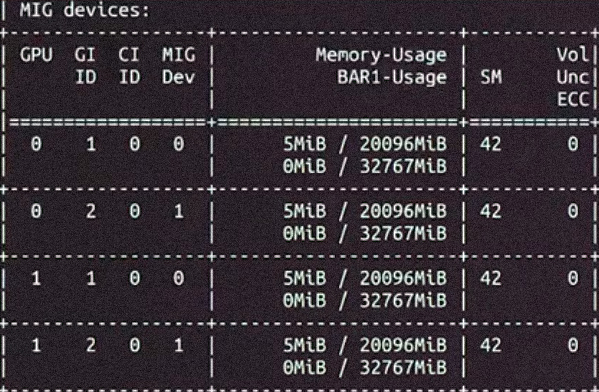
Running vLLM for Local LLMs on Mixed GPUs? MIG Might Just Make It Work.
When I recently helped set up an LLM inference server for a client, I ran into a problem that may sound familiar to anyone mixing different GPUs. I had an RTX Pro 6000 Workstation (95 GB VRAM) and an RTX 5090 (32 GB VRAM). The goal was simple: run vLLM setup without wasting available memory....