-
Nov. 4, 2025 / Hardware Insights
Running vLLM for Local LLMs on Mixed GPUs? MIG Might Just Make It Work.
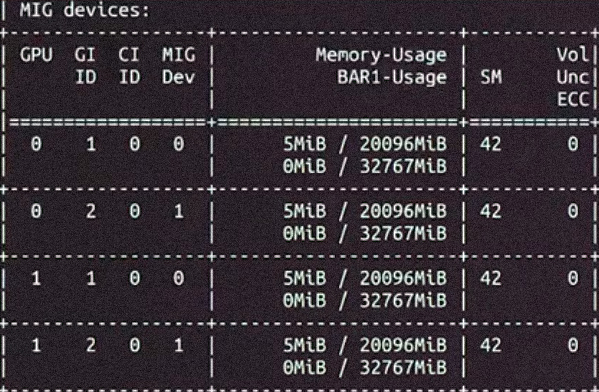
When I recently helped set up an LLM inference server for a client, I ran into a problem that may sound familiar to anyone mixing different GPUs. I had an RTX Pro 6000 Workstation (95 GB VRAM) and an RTX 5090 (32 GB VRAM). The goal was simple: run vLLM setup without wasting available memory....

-
Nov. 3, 2025 / Hardware Insights
Inside PewDiePie’s $41,000 AI PC: 424GB of VRAM for Local LLMs
When one of YouTube’s biggest creators decides to build a personal AI supercomputer, the local LLM scene takes notice. PewDiePie’s journey into AI hardware has produced a multi-GPU, 424GB VRAM workstation that many enthusiasts dream of. While his budget is far beyond the average builder, his component choices and setup offer a valuable blueprint for...

-
Nov. 2, 2025 / Hardware Insights
The Definitive GPU Ranking for LLMs: Token Generation & Prompt Processing Performance
At Hardware Corner, we set out to create a data-driven benchmark hierarchy for local LLM inference – focusing on the two workloads that define real-world performance: prompt processing and token generation. Using llama.cpp’s latest llama-bench on Ubuntu 24.04 with CUDA 12.8, we measured a wide range of GPUs across model sizes, context lengths, and quantization...

-
Oct. 28, 2025 / LLM Benchmarks
LLM VRAM Usage Compared: Benchmarking Popular 8B–123B Models Across 4K–256K Contexts
As someone who runs language models locally, I know that VRAM is the one resource we can never have enough of. Every parameter, every token of context, and the growing KV cache all chip away at that precious memory. To cut through the speculation and get hard data, I decided to benchmark some of today’s...

-
Oct. 24, 2025 / Hardware Insights
Best PC Builds for Local LLMs: From 7B to 123B Models
This guide presents several PC build options at different price points for enthusiasts looking to run large language models (LLMs) on their local machines. These are templates designed for performance and value in LLM inference. You can adjust them based on component availability and your specific budget. At the moment, RAM prices are unusually high,...

-
Oct. 18, 2025 / LLM Hardware News
Llama.cpp Local LLMs on AMD Get 13% Faster Prompt Processing with RADV Vulkan Driver Update
Llama.cpp local LLMs on AMD GPUs just got faster - the latest RADV Vulkan driver update delivers up to 13% higher prompt processing performance

-
Oct. 16, 2025 / LLM Benchmarks
RTX 5090 LLM Benchmark Results: 10K Tokens/sec Prompt Processing, 139K Context
I recently completed extensive local LLM inference benchmarks on the NVIDIA RTX 5090 32 GB. My primary focus was gathering raw performance data on critical metrics for the local enthusiast: prompt processing speed (PP), token generation throughput (TG), and the maximum context window I could sustain using 4-bit quantization (Q4_K_XL). My goal here is to...

-
Oct. 15, 2025 / LLM Hardware News
First Nvidia DGX Spark LLM Benchmarks Are In: Does It Beat Strix Halo
The long-awaited Nvidia DGX Spark is finally here, and the first benchmarks for local LLM inference have landed. Georgi Gerganov of ggml-org has put the machine through its paces with the latest llama.cpp, giving us the raw data we need.
-
Oct. 13, 2025 / LLM Hardware News
Intel’s Nova Lake-AX for Local LLMs – What We Know So Far About AMD’s Halo Competitor
For local LLM enthusiasts, the hardware landscape is in constant motion. We are always searching for the next breakthrough that delivers more VRAM and memory bandwidth for our dollar. While multi-GPU setups using used server cards have been the go-to solution, a new class of powerful APUs, or “big APUs,” is emerging. AMD fired the...

-
Oct. 9, 2025 / How to Run LLMs Localy
How Multi-Token Prediction Makes Local LLMs Faster – Without Extra VRAM.
For anyone running LLMs locally, the goal is always more performance for less cost. We obsess over VRAM, memory bandwidth, and squeezing every last token per second out of our hardware. While prompt processing (TTFT) is often fast, the token generation that follows can be a bottleneck, especially on memory-bandwidth-limited systems. This one-token-at-a-time process, called...

-
Oct. 8, 2025 / How to Run LLMs Localy
I optimized my Strix Halo for local LLMs: Here are the benchmarks and findings.
If you’ve gotten your hands on an AMD Ryzen AI Max+ 395 (Strix Halo) system, you already know the raw hardware is impressive. That massive pool of unified LPDDR5x memory is a game-changer for running large models locally. But unlocking its full potential isn’t just plug-and-play. The key to getting the best possible performance lies...

-
Sep. 29, 2025 / How to Run LLMs Localy
Speculative Decoding Explained: Faster Inference Without Quality Loss
Unlock significant speed gains for large language models on your own hardware without sacrificing quality. Here’s how it works and how to set it up in popular inference engines. Why Local LLMs Run Slow If you run large language models on your own hardware, you know the biggest challenge is inference speed. Getting high-quality models...

-
Sep. 15, 2025 / How to Run LLMs Localy
What Is Context Length in LLMs and How It Impacts Your VRAM (and Speed)
For local LLM enthusiasts, the race for models with larger “context lengths” feels like the next frontier. While developers boast models that can “remember” entire novels, the practical reality for anyone running hardware at home is that a bigger context window directly translates to a massive hit on your system’s resources, especially your precious VRAM....

-
Sep. 11, 2025 / Hardware Insights
GPU First or Model First? The Right Way to Decide on Local LLM Hardware
Let’s be honest: cloud LLMs are incredibly powerful and mostly free. GPT-5, Gemini Pro, Claude Sonnet 4 – you can use them for almost unlimited queries without hitting hard limits. I personally combine Gemini and ChatGPT when one hits a rate limit, and it works perfectly. So why would you want to run models locally?...

-
Sep. 10, 2025 / LLM Benchmarks
Can Three RTX 3090s Really Run GPT-OSS 120B with Max Context? I Put It to the Test
After testing the gpt-oss-20B model on a single RTX 3090, I had to push things further and see what the new heavyweight could do. In addition to the 20B model, OpenAI also released gpt-oss-120B, a massive 120-billion parameter open-weight Mixture-of-Experts (MoE) model with 5.1 billion active parameters. I first ran some experiments on an RTX...

-
Sep. 5, 2025 / How to Run LLMs Localy
Quantization for Local LLMs: How It Works and Which Formats Fit Your Setup
Running large language models locally requires smart resource management. Quantization is the key technique that makes this possible by reducing memory requirements and improving inference speed. This practical guide focuses on what you need to know for local LLM deployment, not the mathematical theory[1] behind it. For the technical mathematical details of quantization, check out...
-
Sep. 4, 2025 / Local LLM
Running LLMs Locally Explained: An Introduction
Large Language Models (LLMs) have rapidly emerged as powerful tools capable of understanding and generating human-like text, translating languages, writing different kinds of creative content, and answering questions in an informative way. You’ve likely interacted with them through services like ChatGPT, Claude, or Gemini. While these cloud-based services offer convenience, there’s a growing interest in...

-
Aug. 31, 2025 / LLM Hardware News
Huawei’s Atlas 300I Duo offers 96GB VRAM for local LLMs under $1500. Is this the budget VRAM breakthrough?
For local LLM enthusiasts, VRAM has always been the main constraint when choosing hardware. Now, a new option is becoming more accessible at a price point that’s hard to ignore. The Huawei Atlas 300I Duo, an AI inference card from China, is showing up on platforms like Alibaba for under $1500, offering an impressive 96...
-
Aug. 27, 2025 / LLM Hardware News
Local LLM VRAM Race: Can AMD’s AT0 Take the Lead From NVIDIA With a 512-Bit Bus?
The latest rumors around AMD’s upcoming RDNA5 flagship, codenamed AT0, suggest a 512-bit memory bus paired with GDDR7. For anyone running large quantized LLMs locally, this is the part of the leak worth paying attention to – not the shader counts or gaming benchmarks. If the leak is accurate, bandwidth and VRAM capacity could finally...

-
Aug. 27, 2025 / LLM Hardware News
LLM VRAM Usage Cut by 45x? What Jet-Nemotron Really Means for Local Users
NVIDIA has just published a paper detailing a new family of language models, Jet-Nemotron, which claims to deliver massive performance gains while maintaining the accuracy of today’s top open-source models. For local LLM users constantly battling VRAM limits and slow inference speeds, this research could point to a significant shift in how we run models...