-
Aug. 23, 2025 / LLM Hardware News
Game-Changer for Local LLMs: AMD Medusa Halo Leak Points to 384-Bit LPDDR6 Bandwidth
Moore’s Law Is Dead has leaked new details on AMD’s upcoming Medusa Halo APU, the direct successor to Strix Halo. For enthusiasts focused on running large language models locally, this is an important development, as Medusa Halo addresses the biggest bottleneck of its predecessor: memory bandwidth. From Strix Halo to Medusa Halo Strix Halo (Ryzen...

-
Aug. 15, 2025 / LLM Hardware News
New local LLM value king – MaxSun Arc Pro B60 Dual with 48GB VRAM for $1200
We recently discussed the upcoming single-GPU Intel Arc Pro B60 with 24GB of VRAM and its potential to shake up the local LLM hardware market. Now, its bigger brother is set to arrive. Reports indicate the MaxSun Arc Pro B60 Dual, featuring two GPUs on a single board for a total of 48GB of VRAM,...
-
Aug. 14, 2025 / LLM Hardware News
Local LLM Users Eye RTX 5070 Ti SUPER and RTX 5080 SUPER After Price Leak Challenges RTX 5090
New pricing information for NVIDIA’s upcoming RTX 50 SUPER series has surfaced, suggesting a significant shift in the value proposition for local large language model (LLM) enthusiasts. According to the leak, the new SUPER cards will launch at the same Manufacturer’s Suggested Retail Price (MSRP) as their non-SUPER predecessors. For anyone building a system for...

-
Aug. 10, 2025 / LLM Hardware News
New Strix Halo Mini-PC Arrives with 96GB Memory, Targeting Sub-$1500 LLM Builds
The stream of mini-PCs built around AMD’s Ryzen AI 300 “Strix Halo” platform continues, this time with a new model named the X+ RIVAL. While the market is quickly becoming crowded with similar hardware, this particular entry is notable for its specific memory configuration and pricing, creating a new value-oriented option for local LLM enthusiasts....

-
Aug. 1, 2025 / LLM Hardware News
LLM-Capable Laptop with 24GB VRAM for Under $1000? AIM’s Strix Halo Prototype Announced
A new prototype laptop from a company called AIM is making waves, not just for being one of the first systems to feature AMD’s powerful Strix Halo APU, but for its alleged sub-$1000 price tag. For the technical enthusiast focused on running large language models locally, this development could signal a major shift in accessible,...

-
Jul. 31, 2025 / LLM Hardware News
I Tested llama.cpp’s New Speed Boost Mode with an RTX 3090 – Here’s What I Found
The development pace in the local LLM scene is relentless, and the team behind llama.cpp has rolled out another interesting update: a new high-throughput mode. The key claim is that by changing how the KV cache is handled for multiple, parallel requests, we can see significant performance gains. As a hands-on enthusiast, I wanted to...

-
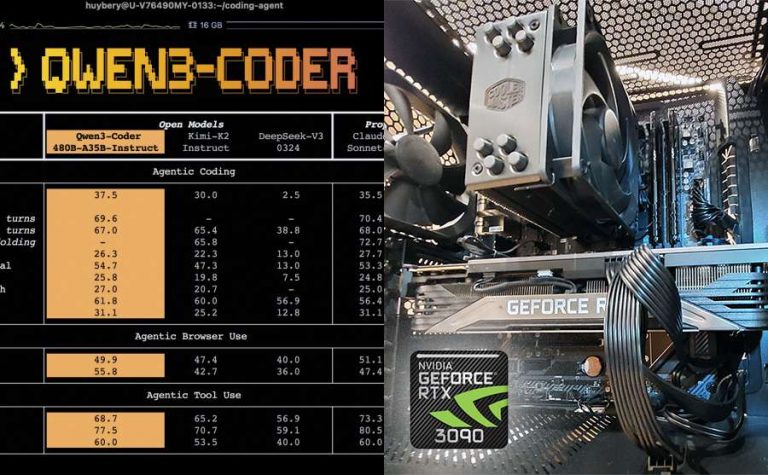
Jul. 24, 2025 / LLM Hardware News
Can Your Computer Run the New Qwen3 Coder 480B LLM Locally?
For local LLM enthusiasts who enjoyed the impressive performance of the Qwen2.5 32B Coder, the recent announcement of the Qwen3-Coder-480B-A35B-Instruct has generated significant excitement. This new, massively powerful model is positioned as a direct competitor to proprietary systems like Claude Code with Sonnet and Google’s Gemini CLI, with a strong focus on agentic coding capabilities....

-
Jul. 23, 2025 / LLM Hardware News
Qwen Unveils 480B Coder LLM and New Command-Line Tool for Local Use
In a significant development for the AI community, the Qwen team has announced the release of its most powerful open agentic code model to date, the Qwen3-Coder-480B-A35B-Instruct. Alongside this powerful new model, the team has also open-sourced Qwen Code, a new AI-powered command-line interface designed to fully leverage the model’s capabilities. Meet the Qwen3 Coder...

-
Jul. 23, 2025 / LLM Hardware News
LLM-Ready Mini-ITX Board With 128GB LPDDR5X Debuts From SIXUNITED
For the do-it-yourself enthusiast focused on building machines for local large language models (LLMs), the hardware market has been dominated by pre-built systems. However, a new option has appeared from SIXUNITED with its STHT1, a Mini-ITX motherboard featuring AMD’s powerful Strix Halo APU. This development offers a new path for builders who prefer to select...

-
Jun. 30, 2025 / LLM Hardware News
RTX 5070 Ti Super Rumored With 24GB VRAM – Plus New Details on RTX 5080 Super and 5070 Super for Local LLMs
Fresh hardware rumors have emerged surrounding NVIDIA’s Blackwell architecture, expanding upon the potential SUPER refresh we discussed in our previous analysis, “Local LLM 24GB and 18GB GPU Options Emerge.” The latest information not only corroborates the existence of the RTX 5080 Super and RTX 5070 Super but introduces a new and potentially crucial SKU for...

-
Jun. 21, 2025 / LLM Hardware News
PELADN Enters the Strix Halo Arena with YO1 Mini-PC for Local LLM
The landscape for high-density, on-premise AI hardware is rapidly evolving, driven almost single-handedly by the arrival of AMD’s Ryzen AI 300 “Strix Halo” series. For the enthusiast dedicated to running large language models locally, these APUs represent a paradigm shift in performance-per-watt and memory capacity within a small form factor. Adding to this burgeoning market,...

-
May. 28, 2025 / LLM Hardware News
FEVM FA-EX9 Mini PC Benchmarked: 128GB Strix Halo for Local LLM Inference
The arrival of AMD’s Ryzen AI MAX+ 395 “Strix Halo” APU has generated considerable interest among local LLM enthusiasts, promising a potent combination of CPU and integrated graphics performance with substantial memory capacity. One of the first systems to showcase this new silicon is the FEVM FA-EX9 Mini PC. Following recent news announcements detailing its...

-
May. 25, 2025 / LLM Hardware News
128GB RAM, Ryzen AI MAX+, $1699 — Bosman Undercuts All Other Local LLM Mini-PCs
The landscape for accessible, high-memory hardware tailored for local Large Language Model (LLM) inference is witnessing an intriguing development. A lesser-known manufacturer, Bosman, has unveiled its M5 AI Mini-PC, promising AMD’s potent Ryzen AI MAX+ 395 “Strix Halo” APU paired with a substantial 128GB of LPDDR5X memory, all reportedly carrying a promotional price tag of...

-
May. 15, 2025 / LLM Hardware News
Zotac Joins the Local LLM Race with Strix Halo Mini-PC — What You Need to Know
Zotac unveils plans for the Magnus EA mini-PC with AMD Strix Halo APU, aiming to bring powerful local LLM inference to compact, GPU-free systems. Expected to support up to 128GB LPDDR5X memory, ideal for running 70B large language models without the complexity of multi-GPU setups. Launching at Computex 2025.

-
May. 11, 2025 / LLM Hardware News
I Analyzed NVIDIA’s RTX PRO 5000 Specs – Here’s What Stands Out for Local LLM Work
NVIDIA has officially announced the RTX PRO 5000 48GB, the latest addition to its professional GPU lineup based on the new Blackwell architecture. Arriving on the heels of its more formidable sibling, the RTX PRO 6000 Blackwell, the RTX PRO 5000 carves out a distinct niche, particularly for the price-conscious enthusiast building systems for local...

-
May. 8, 2025 / LLM Hardware News
Forget Used RTX 3090s – Intel’s 24GB Arc Pro B60 Could Be the Better Buy for Local LLM
Intel is poised to expand its professional graphics lineup with the Arc Pro Battlemage series, confirmed for a reveal at Computex. Among the anticipated offerings, one model, the Arc Pro B60, is set to feature a significant 24GB of VRAM. This development is particularly noteworthy for the burgeoning community of enthusiasts running large language models...

-
May. 7, 2025 / LLM Hardware News
LLM Mini PC War Is On: Beelink Enters the Race with $1,800 Strix Halo-Powered GTR9 Pro AI
Beelink has unveiled the GTR9 Pro AI Mini, a compact LLM-ready PC powered by the Ryzen AI MAX+ 395 APU with up to 128GB RAM and 110GB usable VRAM.

-
May. 7, 2025 / LLM Hardware News
Local LLM on a Budget? CUDA Deprecation Spells Trouble for DIY AI Rigs Using P40, V100, 1080 Ti
The architectures facing this CUDA end-of-life span a significant period of Nvidia's GPU development, from early 2014 to 2017, and include many cards that have become staples in budget-conscious LLM rig
-
May. 2, 2025 / LLM Hardware News
Running 671B Models Locally? This $20K Chinese LLM Box Does It with 1 GPU, 1TB of RAM, and 20 Tokens/Sec
Xingyun's core strategy appears to be treating this vast, high-bandwidth system RAM pool as the primary storage for the LLM weights, rather than relying solely, or even primarily, on GPU VRAM.
-
Apr. 28, 2025 / LLM Hardware News
Local LLM 24GB and 18GB GPU Options Emerge: RTX 5070 SUPER and 5080 SUPER Hint at VRAM Gains for Inference
From a local LLM perspective, the rumored 24GB VRAM capacity of the RTX 5080 SUPER is the headline feature. This VRAM pool significantly expands the horizons for model deployment on consumer-grade hardware