Fresh hardware rumors have emerged surrounding NVIDIA’s Blackwell architecture, expanding upon the potential SUPER refresh we discussed in our previous analysis, “Local LLM 24GB and 18GB GPU Options Emerge.” The latest information not only...
The landscape for high-density, on-premise AI hardware is rapidly evolving, driven almost single-handedly by the arrival of AMD’s Ryzen AI 300 “Strix Halo” series. For the enthusiast dedicated to running large language models locally, these APUs represent...
The arrival of AMD’s Ryzen AI MAX+ 395 “Strix Halo” APU has generated considerable interest among local LLM enthusiasts, promising a potent combination of CPU and integrated graphics performance with substantial memory capacity. One of the first...
The landscape for accessible, high-memory hardware tailored for local Large Language Model (LLM) inference is witnessing an intriguing development. A lesser-known manufacturer, Bosman, has unveiled its M5 AI Mini-PC, promising AMD’s potent Ryzen AI MAX+ 395...
The small form factor (SFF) PC landscape for local large language model (LLM) inference is set to gain another contender, as Zotac has signaled its intent to launch the Magnus EA series, reportedly featuring AMD’s Ryzen AI MAX+ 395 “Strix Halo” APU,...
NVIDIA has officially announced the RTX PRO 5000 48GB, the latest addition to its professional GPU lineup based on the new Blackwell architecture. Arriving on the heels of its more formidable sibling, the RTX PRO 6000 Blackwell, the RTX PRO 5000 carves out a distinct...
Intel is poised to expand its professional graphics lineup with the Arc Pro Battlemage series, confirmed for a reveal at Computex. Among the anticipated offerings, one model, the Arc Pro B60, is set to feature a significant 24GB of VRAM. This development is...
The landscape for compact, high-memory systems capable of local Large Language Model (LLM) inference is steadily expanding, with Beelink now officially announcing its GTR9 Pro AI Mini. This unit joins a growing roster of Mini-PCs built around AMD’s Ryzen AI MAX+...
Nvidia has officially signaled a significant transition in its CUDA ecosystem, announcing in the CUDA 12.9 Toolkit release notes that the next major toolkit version will cease support for Maxwell, Pascal, and Volta GPU architectures. While these venerable...
The landscape of local large language model (LLM) inference is often defined by the limitations of GPU VRAM. Enthusiasts meticulously plan multi-GPU setups, hunt for deals on used high-VRAM cards, and carefully select quantization levels to squeeze models onto their...
The latest whispers from the hardware grapevine suggest NVIDIA might be preparing SUPER variants for its RTX 50 series, specifically an RTX 5080 SUPER and an RTX 5070 SUPER. While mid-generation refreshes are standard practice, these rumored SKUs are particularly...
The landscape for local LLM inference hardware has just become more interesting with recent developments in NVIDIA’s memory supply chain. SK Hynix has joined Samsung as a GDDR7 memory supplier for the GeForce RTX 50 series, with initial implementations appearing...
https://fagus.fra1.digitaloceanspaces.com/tmp/audio/strix-halo-mini-pc-for-local-llm-Inference.mp3 Chinese manufacturer FAVM has announced FX-EX9, a compact 2-liter Mini-PC powered by AMD’s Ryzen AI MAX+ 395 “Strix Halo” processor, potentially...
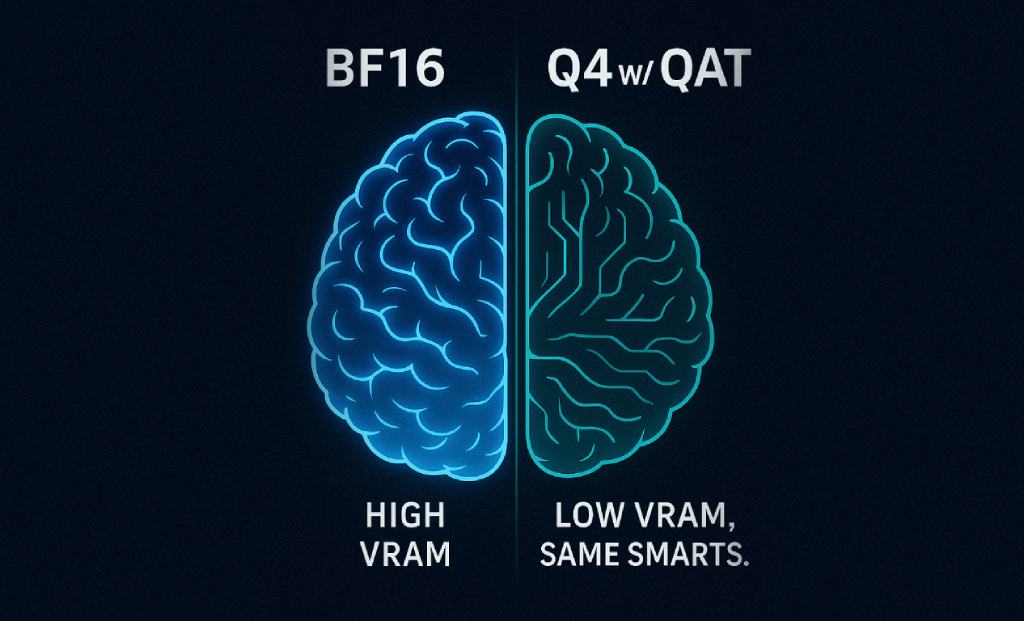
Google has introduced a breakthrough optimization technique called Quantization-Aware Training (QAT) for their Gemma 3 large language models, dramatically reducing the memory requirements needed to run these powerful AI systems on consumer hardware while preserving...
In a significant move for the local LLM inference community, Intel has announced that it’s open sourcing AI Playground, its versatile platform for generative AI that was previously exclusive to Intel hardware. This development comes at a critical time as AMD...
The much-anticipated NVIDIA RTX 5060 Ti has finally hit retail shelves, with the 16GB model now available from major retailers like Newegg and Best Buy. Initial pricing has settled between $470-$570 for most standard models, representing a modest 10-23% premium over...
NVIDIA has officially unveiled the RTX 5060 Ti with 16GB of GDDR7 memory at $429, positioning it as a compelling option for local LLM enthusiasts. At this price point, the card not only offers excellent standalone value but opens up an even more enticing possibility:...
In just two days, NVIDIA is set to launch their RTX 5060 Ti, and recently leaked specs suggest this card could become the go-to option for budget-conscious LLM enthusiasts looking to run impressive models locally. With the rising prices and dwindling availability of...
The landscape of local large language model (LLM) inference is evolving at a breakneck pace. For enthusiasts building dedicated systems, maximizing performance-per-dollar while navigating the ever-present VRAM ceiling is a constant challenge. Following closely on the...
Tenstorrent, the AI and RISC-V compute company helmed by industry veteran Jim Keller, has officially opened pre-orders for its new lineup of Blackhole and Wormhole PCIe add-in cards. Aimed squarely at developers and, potentially, the burgeoning local Large...