Local LLM Inference Just Got Faster: RTX 5070 Ti With Hynix GDDR7 VRAM Overclocked to 1088 GB/s Bandwidth

The landscape for local LLM inference hardware has just become more interesting with recent developments in NVIDIA’s memory supply chain. SK Hynix has joined Samsung as a GDDR7 memory supplier for the GeForce RTX 50 series, with initial implementations appearing on RTX 5070 Ti cards in the Chinese market. For the local LLM enthusiast community, this development brings some implications for performance optimization and value considerations.
LLM Inference
While VRAM capacity often dominates discussions about local LLM inference (determining the maximum model size you can run), memory bandwidth is equally critical for actual performance. When processing tokens through quantized models, the speed at which the GPU can access and move model weights becomes a primary performance constraint. This is where the new GDDR7 memory overclocking capabilities become particularly relevant.
The Bandwidth
Testing from users in China has confirmed that SK Hynix GDDR7 memory modules – nominally rated at 28 Gbps – can be safely overclocked to 34 Gbps.
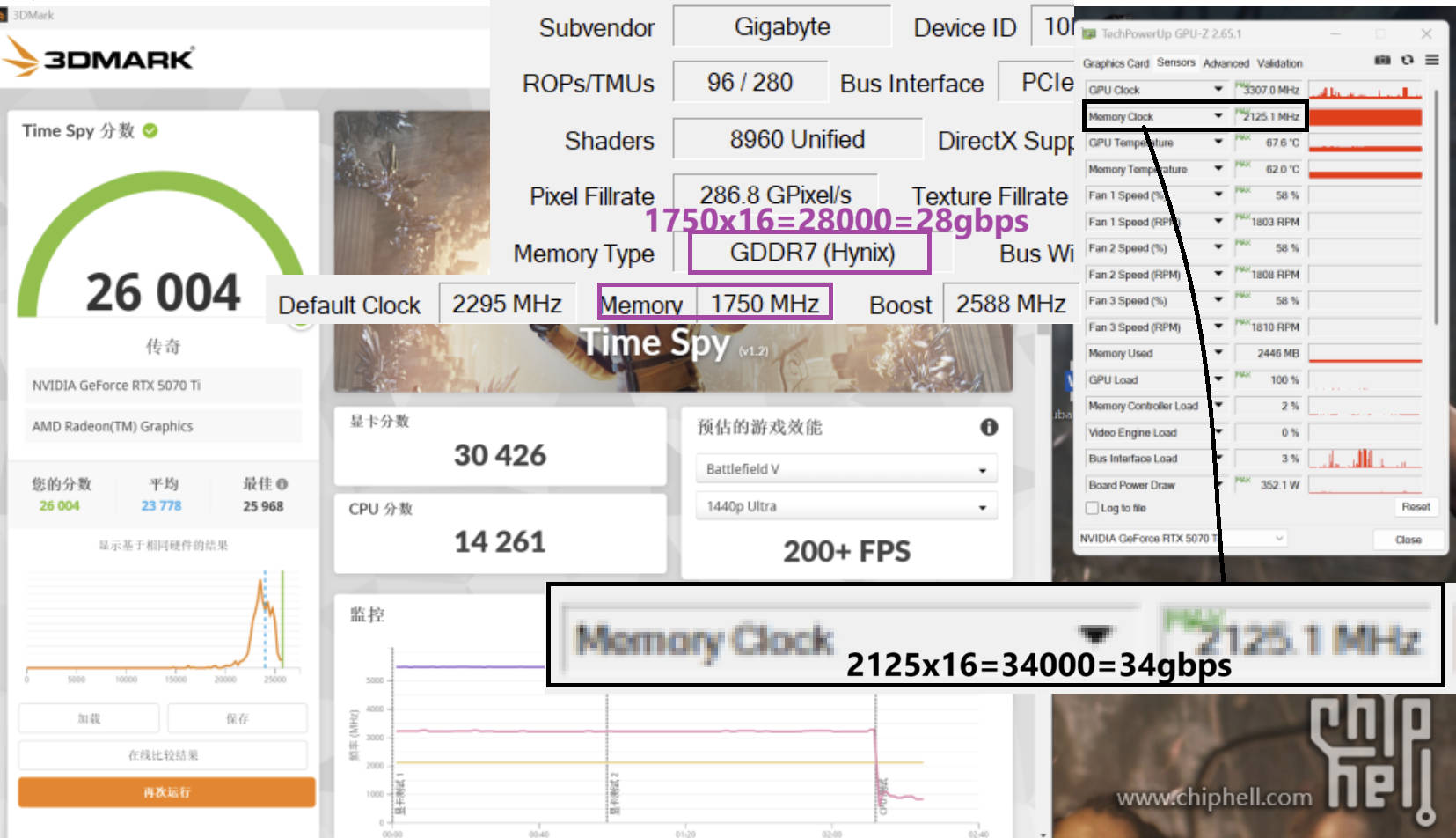
This represents a substantial increase in effective memory bandwidth:
- RTX 5070 Ti: From stock 896.0 GB/s to an overclocked 1088 GB/s
- RTX 5070 (12GB): From stock 672.0 GB/s to an overclocked 816 GB/s
The overclocked RTX 5070 Ti now matches the memory bandwidth of the flagship RTX 4090 (1088 GB/s), albeit with 16GB rather than 24GB of VRAM. For context, this bandwidth increase directly translates to faster token generation when running models that fit within the card’s memory envelope.
Practical Implications for LLM Enthusiasts
What does this mean for the price-conscious LLM enthusiast? The enhanced memory bandwidth translates to approximately 21% faster inference speeds when running memory-bandwidth-limited workloads. For typical 7B parameter models in 4-bit quantization, this could mean the difference between 25 tokens/second and 30+ tokens/second, significantly improving the responsiveness of your local AI assistant.
It’s worth noting that both SK Hynix and Samsung GDDR7 modules appear to offer similar overclocking headroom, so the memory supplier shouldn’t be a decisive factor in purchasing decisions.
Value Proposition
Despite these impressive technical capabilities, current pricing presents a mixed value proposition for dedicated LLM enthusiasts:
- At approximately $900, the RTX 5070 Ti remains expensive relative to alternatives in the second-hand market
- For pure LLM inference workloads, a used RTX 3090 (24GB VRAM, 936 GB/s bandwidth) at $850 still offers superior value, particularly for running larger 32B parameter models in 4-bit quantization
However, looking forward, as RTX 5070 Ti prices inevitably drop, a dual-GPU configuration becomes particularly compelling. Two overclocked RTX 5070 Ti cards would provide 32GB of combined VRAM with industry-leading bandwidth, enabling inference on larger models with exceptional performance.
Implementation Considerations
For those looking to implement these overclocks:
- Use MSI Afterburner or similar utilities to gradually increase memory clocks, testing stability at each step
- Monitor temperatures carefully, as GDDR7 at 34 Gbps will generate additional heat
- Be aware that cross-flashing BIOS between cards with different memory suppliers may cause issues; stick with your card’s original BIOS unless absolutely necessary
Memory overclocking on GDDR7 appears more stable than previous generations, with most cards able to achieve the full 34 Gbps with minimal voltage adjustments.
Future Outlook
As price erosion continues in the GPU market, the overclocking headroom of GDDR7 memory makes the RTX 5070 series increasingly attractive for LLM inference workloads. A dual RTX 5070 Ti configuration at sub-$1300 could become the sweet spot for local LLM enthusiast.
Read more




No comments yet.