LLM Hardware News
Latest LLM hardware news! Discover GPU releases, memory bandwidth advancements, and new platforms for running large language models locally.
Running 671B Models Locally? This $20K Chinese LLM Box Does It with 1 GPU, 1TB of RAM, and 20 Tokens/Sec

Inference
Local LLM 24GB and 18GB GPU Options Emerge: RTX 5070 SUPER and 5080 SUPER Hint at VRAM Gains for Inference

VRAM
Local LLM Inference Just Got Faster: RTX 5070 Ti With Hynix GDDR7 VRAM Overclocked to 1088 GB/s Bandwidth

Inference, VRAM
New Chinese Mini-PC with AI MAX+ 395 (Strix Halo) and 128GB Memory Targets Local LLM Inference

Strix Halo
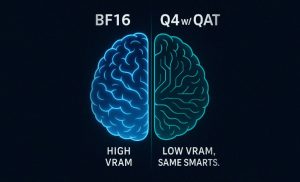
Smarter Local LLMs, Lower VRAM Costs – All Without Sacrificing Quality, Thanks to Google’s New QAT Optimization
VRAM
Arc GPUs Paired with Open-Source AI Playground Offer Flexible Local AI Setup

GPU
RTX 5060 Ti for Local LLMs: It’s Finally Here – But Is It Available, and Is the Price Still Right?

Dual RTX 5060 Ti: The Ultimate Budget Solution for 32GB VRAM LLM Inference at $858

GPU
55% More Bandwidth! RTX 5060 Ti Set to Demolish 4060 Ti for Local LLM Performance

GPU